
Évaluer l'IA pour la Prise de Décision en Contexte d'Incertitude
Une perspective sur l'évaluation des résultats de l'IA dans les contextes de gouvernance, plaidant pour une évaluation centrée sur la décision, fondée sur l'incertitude, la rationalité limitée et les principes de gouvernance d'entreprise.
Évaluation des LLM Centrée sur la Décision en Contexte d'Incertitude
La plupart des approches d'évaluation de l'IA partent du principe que l'objectif est de produire un texte correct, complet et bien formulé. Cet article soutient que de telles hypothèses s'effondrent dans les contextes de gouvernance réels. Lorsque des décisions doivent être prises dans un contexte d'incertitude, avec des données incomplètes et bruitées, la question pertinente n'est pas de savoir si un résultat est parfait, mais s'il conduit à la bonne décision au bon niveau. Cette perspective présente une alternative : une approche d'évaluation de l'IA centrée sur la décision et fondée sur l'incertitude, la rationalité limitée et la gouvernance d'entreprise.
Perspective Kanita
L'évaluation de l'IA est souvent structurée autour de l'exactitude, de l'exhaustivité et de la qualité linguistique. Ce cadre fonctionne bien pour des tâches telles que le résumé, les questions-réponses ou la génération de contenu. Il devient cependant insuffisant dans le contexte où opère Kanita (www.kanita.se) : la gouvernance, les risques et la prise de décision exécutive sous incertitude et pression temporelle.
Kanita produit des rapports de triage de gouvernance à partir de données incomplètes, bruitées et souvent ambiguës. Dans sa forme la plus contrainte, le système peut s'appuyer uniquement sur des informations accessibles au public dérivées d'une seule URL. Cela constitue un environnement de signaux délibérément faibles, où la qualité des données est intrinsèquement limitée et inégale.
L'hypothèse sous-jacente n'est pas que l'IA produira des analyses entièrement correctes ou exhaustives, mais que les décideurs bénéficient souvent de signaux précoces et imparfaits plutôt que de rapports complets mais tardifs. L'objectif n'est donc pas l'exhaustivité analytique, mais la transformation de données d'entrée faibles et fragmentées en orientations structurées et pertinentes pour la décision.
Au cœur de l'approche Kanita se trouve la matrice de triage :
- AUTORISER (ALLOW) — poursuivre dans le cadre de la gouvernance actuelle
- SUSPENDRE (FREEZE) — faire une pause jusqu'à ce que la responsabilité et les risques soient clarifiés
- DÉCISION FORMELLE REQUISE — faire remonter au niveau exécutif
Cette structure réduit l'ambiguïté en catégories exploitables et aligne l'urgence sur le niveau organisationnel approprié. Si des sources de données internes et structurées plus riches peuvent considérablement améliorer la qualité des résultats, une plus grande exhaustivité de l'information ne conduit pas nécessairement à de meilleures décisions. Dans des environnements de grande incertitude, la clarté du signal l'emporte souvent sur l'exhaustivité de l'analyse.
Cette perspective s'aligne sur des concepts bien établis tels que le modèle VUCA (Volatilité, Incertitude, Complexité, Ambiguïté) et la prise de décision en contexte d'incertitude, où l'objectif n'est pas d'éliminer l'incertitude mais d'agir efficacement malgré elle.
De la Qualité du Texte au Signal de Décision
Les cadres d'évaluation classiques des modèles de langage — y compris les suites de référence telles que HELM (Holistic Evaluation of Language Models) et les approches similaires — mettent l'accent sur des dimensions telles que l'exactitude, la calibration, la robustesse et la qualité linguistique. Ces cadres sont appropriés lorsque la vérité de référence (ground truth) est bien définie ou lorsque les résultats peuvent être évalués par rapport à des réponses de référence stables.
Cependant, dans les contextes de gouvernance et de risque, de telles références sont souvent indisponibles ou fondamentalement ambiguës. La question n'est pas de savoir si un rapport est « correct » dans un sens absolu, mais s'il soutient une prise de décision appropriée compte tenu d'informations incomplètes.
Par conséquent, Kanita recadre l'évaluation autour de trois questions principales : le résultat produit-il un signal de décision approprié, l'escalade est-elle placée au bon niveau organisationnel, et les risques les plus pertinents sont-ils exposés avec suffisamment de clarté pour permettre l'action.
L'unité d'évaluation n'est donc pas le texte lui-même, mais son impact fonctionnel sur la prise de décision.
Cette perspective synthétise les enseignements de plusieurs domaines de recherche : l'évaluation des LLM (comparaison par paires et évaluation par modèle), la recherche d'informations (pertinence plutôt qu'exhaustivité) et les sciences de la décision (rationalité limitée et satisfaction satisfaisante - satisficing). Ensemble, ces domaines suggèrent que l'utilité en contexte d'incertitude est une cible d'évaluation plus pertinente que la fidélité textuelle.
Opérer en Contexte d'Incertitude
Le contexte de Kanita se définit par trois contraintes structurelles : des données incomplètes et bruitées, des environnements de décision à enjeux élevés, et un temps d'analyse limité. Il ne s'agit pas de limites temporaires — ce sont des propriétés intrinsèques de la gouvernance et des risques dans le monde réel.
Cela a deux implications majeures.
Premièrement, cela rend les notions traditionnelles « d'exactitude » insuffisantes. Lorsque les données sont partielles, ambiguës ou faiblement justifiées, il n'existe souvent aucune vérité de référence stable permettant d'évaluer les résultats. Toute tentative d'optimisation en vue d'une exactitude parfaite dans un tel cadre conduira soit à une fausse précision, soit à la paralysie.
Deuxièmement, cela déplace le problème de l'analyse vers celui de la prise de décision sous contrainte. Cela rejoint les principes établis dans les sciences de la décision :
- La rationalité limitée (Herbert Simon) — les décisions sont prises sous des contraintes de temps, d'information et de capacité cognitive
- Le satisficing — l'objectif n'est pas de prendre des décisions optimales, mais des décisions suffisamment bonnes pour pouvoir agir
La pertinence de ces concepts est directe. Si les décideurs opèrent avec une rationalité limitée, les cadres d'évaluation doivent refléter ces mêmes contraintes. Les résultats ne doivent pas être jugés sur leur exhaustivité ou leur précision dans l'absolu, mais sur leur capacité à soutenir efficacement l'action dans ces limites.
Cela conduit à une définition différente de ce que signifie « bon ».
Un bon résultat n'est pas celui qui élimine l'incertitude, mais celui qui :
- structure l'incertitude en un signal de décision clair
- place ce signal à un niveau d'escalade approprié
- permet d'agir en temps utile sans outrepasser les preuves sous-jacentes
En d'autres termes, la qualité est définie par l'adéquation de la décision en situation d'incertitude, et non par l'exhaustivité analytique ou la correction textuelle.
Par conséquent, Kanita évalue les résultats en fonction de leur capacité à produire des signaux de décision utilisables et correctement calibrés à partir de données imparfaites.
À Quoi Ressemble un "Bon" Rapport
Définir ce qui constitue un "bon" rapport dans ce contexte est complexe. Contrairement aux tâches disposant d'une vérité de référence claire, le triage de gouvernance opère dans l'ambiguïté, l'information partielle et les interprétations concurrentes. En conséquence, les critères ci-dessous ne doivent pas être considérés comme définitifs ou exhaustifs, mais comme des heuristiques dérivées, fondées sur les contraintes et les fondements théoriques présentés précédemment.
Plus précisément, ils découlent de :
- la rationalité limitée (décisions sous contrainte d'information et de temps)
- le satisficing (préférence pour une adéquation actionnable plutôt qu'une exhaustivité optimale)
- l'évaluation basée sur la pertinence (utilité plutôt qu'exactitude absolue)
De ce point de vue, un « bon » rapport est celui qui semble remplir plusieurs conditions concomitantes.
Premièrement, il doit attribuer une catégorie de triage raisonnable. Dans un contexte d'incertitude, une classification exacte est souvent hors de portée ; cependant, le rapport doit positionner le problème dans une marge de décision plausible (par exemple, en ne sous-estimant ou en ne surestimant pas significativement le risque). Cela reflète le principe du satisficing plutôt qu'une optimisation précise.
Deuxièmement, il doit placer la décision à un niveau organisationnel approprié. Cela découle de la théorie de la gouvernance (p. ex. COSO ERM), selon laquelle la qualité d'une décision est en partie déterminée par le fait de savoir si elle est assumée au bon niveau de responsabilité.
Troisièmement, il doit identifier les thèmes pertinents de gouvernance et de risque. S'inspirant des principes de recherche d'informations, le but n'est pas d'être exhaustif, mais de capter les signaux les plus pertinents pour la décision (ex. : exposition réglementaire, lacunes en matière de responsabilité, problèmes de traçabilité).
Quatrièmement, il doit permettre des discussions et des actions concrètes. Conformément à la rationalité limitée, les résultats doivent réduire la charge cognitive plutôt que l'augmenter. Un rapport riche d'un point de vue analytique mais opérationnellement ambigu présente une valeur limitée.
Cinquièmement, il doit démontrer une gestion appropriée de l'incertitude. Cela inclut d'expliciter les hypothèses, d'éviter les précisions injustifiées et de distinguer l'observation de la déduction. Ceci s'aligne sur une calibration épistémique plutôt que sur une exhaustivité factuelle.
Ces dimensions sont interdépendantes plutôt que des métriques isolées, et l'on s'attend à des compromis. En particulier, deux modes d'échec sont régulièrement observés :
- La surconfiance fondée sur des signaux faibles, où le rapport exagère la certitude ou procède à une escalade sans fondement suffisant.
- La prudence excessive, où l'incertitude est gérée de manière si conservatrice qu'il ne reste plus aucun signal concret.
Un « bon » résultat n'élimine pas ces tensions, mais les équilibre. Il est suffisamment structuré pour soutenir l'action, tout en restant convenablement calibré par rapport aux limites des données sous-jacentes.
En ce sens, la qualité s'apparente moins à l'exactitude qu'à l'adéquation de la décision face à l'incertitude.
Comment Fonctionne L'Évaluation (Méthode Initiale)
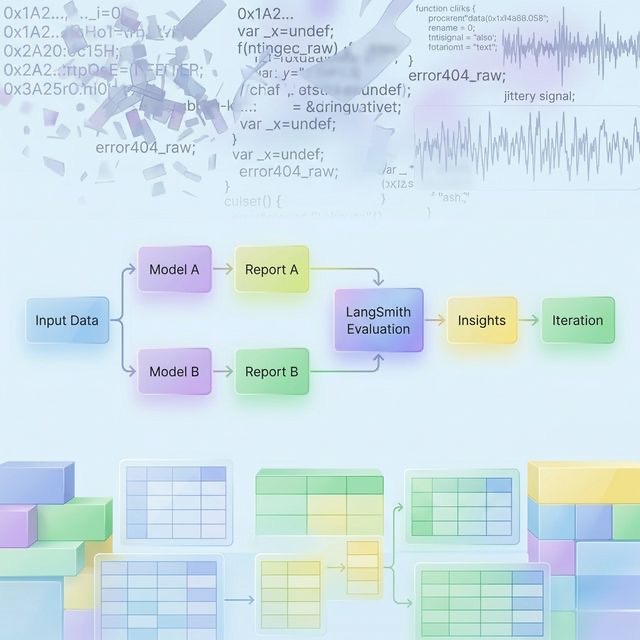
L'implémentation actuelle représente une méthode initiale permettant d'évaluer les résultats du triage de gouvernance sur l'ensemble de différents modèles et configurations.
Plusieurs rapports sont générés à partir des mêmes données de base, en utilisant différents modèles (ex. : Google Gemini, Mistral) et de différentes tailles. Cela crée un ensemble de comparaison contrôlé où les variations s'expliquent par le comportement du modèle plutôt que par des différences d'entrée.
Les résultats obtenus sont évalués dans LangSmith en combinant :
- L'évaluation comparative (pairwise)
- Un scoring structuré par dimension
Ce dispositif permet d'obtenir à la fois un classement (quel est le meilleur rapport) et des informations diagnostiques (pourquoi est-il meilleur).
Évaluation comparative
Les rapports sont évalués par paires. La question centrale est :
Quel rapport soutient le mieux la prise de décision de la direction ?
La comparaison par paires est empiriquement plus robuste que le classement absolu dans les contextes caractérisés par l'ambiguïté et l'absence d'une vérité absolue.
Dimensions structurées
Chaque rapport est également évalué selon une série de dimensions définies :
- l'exactitude du triage
- l'exactitude du niveau de décision
- la pertinence du risque
- l'utilité pour la décision
- la discipline face à l'incertitude
- la discipline en matière d'affirmations (éviter les conclusions sans preuve)
Ces dimensions sont mesurées à l'aide d'échelles ordinales, afin de préserver l'interprétabilité et de limiter le risque de fausse précision.
Du point de vue de la gouvernance, ces dimensions peuvent également être appréhendées sous l'angle de COBIT :
- Exactitude du triage → correspond à la nécessité de veiller à ce que les risques soient correctement évalués et que les mesures de contrôle appropriées soient déclenchées (optimisation du risque)
- Exactitude du niveau de décision → reflète la juste allocation des droits de décision et des responsabilités (gouvernance vs responsabilités de gestion)
- Pertinence du risque → correspond à l'identification et à la priorisation des risques d'entreprise affectant la création de valeur
- Utilité de la décision → soutient la création de valeur en permettant des décisions rapides et actionnables
- Discipline face à l'incertitude → se rapporte au maintien d'un niveau d'assurance convenable et au refus des fausses certitudes dans les contrôles et les rapports
- Discipline en matière d'affirmations → alignée sur l'intégrité et la fiabilité des informations utilisées pour la gouvernance et les décisions
Cette mise en correspondance confirme que les dimensions d'évaluation ne sont pas arbitraires, mais s'accordent avec les principes établis de la gouvernance informatique et de la gestion des risques de l'entreprise.
De façon plus spécifique, ce cadre de travail peut être interprété comme une adaptation légère et axée sur la décision des principes COBIT face à l'incertitude. Notamment :
- EDM (Évaluer, Diriger, Surveiller) → traduit par l'exactitude du triage et l'exactitude du niveau de décision, garantissant que les bons problèmes sont signalés et gouvernés au niveau approprié
- APO (Aligner, Planifier, Organiser) → traduit par la pertinence du risque et l'utilité pour la décision, en reliant les risques ciblés à des réponses organisationnelles possibles
- BAI (Bâtir, Acquérir, Implanter) → traduit implicitement par l'incertitude et la prudence des affirmations, garantissant que les décisions influençant les projets soient mesurées selon les données probantes
Cette interprétation place le cadre d'évaluation non pas comme une alternative aux modèles de gouvernance existants, mais comme une couche complémentaire dédiée à la structuration initiale du signal et à l'aide à la décision.
Comment les dimensions sont évaluées
Chaque dimension est évaluée à l'aide de signaux observables étudiés au regard du résultat obtenu plutôt que de par une simple approche subjective.
Exactitude du triage
- L'action recommandée (AUTORISER / SUSPENDRE / DÉCISION FORMELLE) correspond-elle au niveau de risque décrit ?
- Signaux "rouges" : Sous-évaluation pour des enjeux de conformité/sécurité, ou sur-réaction face à un cas mineur.
Exactitude du niveau de décision
- La situation est-elle reportée au bon niveau de décision au sein de l'organisation (équipe projet, DSI, comité exécutif) ?
- Signal : Cohérence entre la portée des risques et les compétences attribuées au preneur de décision.
Pertinence du risque
- Les risques de gouvernance majeurs sont-ils correctement ciblés ?
- Signal : La présence de thèmes critiques (contrainte réglementaire par ex. IA Act, problème de suivi/traçabilité de la logique, niveau de dépendance par rapport à des services tiers).
Utilité pour la décision
- Peut-on prendre une action sur-le-champ au regard du rapport ?
- Signal : Clarté dans la prochaine action à mener, pas d'ambiguïté pour poursuivre.
Discipline face à l'incertitude
- Le rapport mesure-t-il correctement la valeur supposée et avérée des arguments ?
- Signal : Le distinguo s'opère sur la base des points réellement établis à opposer des inconnues et inférences.
Discipline en matière d'affirmations
- Les affirmations en phase d'évaluation par l'IA restent-elles en accord avec les preuves initiales ?
- Signal : L'ignorance est préservée pour ne pas prétendre à un niveau de certitude que la matière première de départ n'offre pas par la surenchère des caractéristiques supposées ou prétendues.
Tableau d'exemple : Bon vs Faibles résultats
| Dimension | Exemple probant | Faible pertinence d'évaluation |
|---|---|---|
| Exactitude du triage | Renvoi à DÉCISION FORMELLE justifié par le domaine (système IA touchant à la sécurité soulevée d'office par les exigences réglementaires. | Ne pose l'attention sur aucune anomalie et opère dans AUTORISER avec un motif creux. |
| Exactitude du niveau de décision | Précise l'ampleur d'une question transversale comme étant sous tutelle du DSI. | Renvoie le souci organisationnel de structuration comme incombant seulement aux compétences du projet opérationnel. |
| Pertinence du risque | Met l'attention sur l'IA Act Européenne, soulevant une lacune sur la notion d'évaluation qualité (QA). | Maintient son contenu sur l'impact de l'IA abordé à un niveau de généralisation sans corrélation concrète |
| Utilité pour la décision | Statut de validation exigé comme préambule de la pause d'un déploiement opérationnel justifié par des tests supplémentaires de contrôle ("Pause: clarifier la notion de processus IA évaluée") | Relate la condition en présence mais s'arrête en ne fournissant pas d'action recommandée en terme de statut de déploiement à prendre |
| Discipline face à l'incertitude | Formalise le constat qu'au moment t la donne reste sur la présence d'Inconnues et préserve l'équilibre par les faits présentés | Fait montre des hypothèses produites par IA tel que statuées sans nuances ni doutes dans sa forme certifiée. |
| Discipline en matière d'affirmations | Privilégie le choix d'un ton mesuré pour toutes les perspectives risquées de l'évaluation non prouvée (ex: risque lié à certains modèles LLMs) | Formalise par une narration orientée avec détermination que le service tier va rompre la dynamique d'évaluation. |
Cette méthode initiale est conçue pour être itérative. Les retours d'évaluation ne sont pas seulement utilisés pour comparer les modèles, mais aussi pour améliorer la conception des prompts, la sélection des modèles et le système Kanita dans le futur.
Ancrer la Subjectivité
C'est probablement la partie la plus difficile du cadre de travail. En pratique, la valeur d'un rapport n'est pas déterminée uniquement par sa qualité interne, mais par ce qu'il accomplit dans un véritable contexte opérationnel. Un rapport peut être jugé "bon" parce qu'il est bien calibré d'un point de vue analytique, ou parce qu'il aide un décideur à faire émerger un problème négligé mais important. Cependant, il peut également être jugé "bon" pour des raisons moins justifiables : parce qu'il soutient un programme préétabli, amplifie une préoccupation favorisée, ou arrive à un moment où l'organisation y est particulièrement réceptive.
Idée centrale :
Un rapport peut être efficace dans la pratique pour des raisons autres que sa qualité analytique pure.
Cela crée une distinction critique entre trois concepts liés mais différents :
- Qualité analytique — à quel point le rapport reflète les preuves disponibles et gère l'incertitude
- Acceptation organisationnelle (Uptake) — si le rapport est accepté, discuté ou suivi d'effet
- Impact sur la décision — si le rapport conduit à des décisions judicieuses ou pertinentes au fil du temps
Ces éléments ne s'alignent pas toujours. Un rapport peut connaître une forte acceptation mais une faible qualité analytique (ex : en renforçant un "sujet favori" interne), ou une haute qualité analytique mais une faible acceptation (ex : en raison d'un mauvais timing ou du manque de préparation de l'organisation).
Pour cette raison, Kanita considère la subjectivité non pas comme un bruit parasite qui peut simplement être supprimé, mais comme faisant partie intégrante du phénomène étudié. Le test pratique réside donc dans "l'épreuve du feu" : un ensemble limité de cas réels est collecté dans le but d'observer comment les rapports sont reçus, utilisés et interprétés dans les contextes de décision formelle.
Cette perspective est cohérente avec les recherches sur l'incertitude et la rationalité écologique, en particulier les travaux de Gerd Gigerenzer. L'une de leurs enseignements majeurs est que les jugements ne doivent pas être évalués de manière abstraite uniquement, mais par rapport aux environnements dans lesquels ils sont employés. Dans des environnements incertains, des heuristiques simples peuvent surperformer face à des modèles complexes si elles sont bien adaptées à la structure de la tâche. Par extension, l'utilité d'un rapport de gouvernance ne peut pas être mesurée aux seules propriétés textuelles ; il faut l'étudier au niveau du contexte, de la synchronisation (timing) mais également au niveau de la démarche que le rapport vise à supporter.
Cela trouve par ailleurs un écho dans les recherches portant sur la compréhension des flux et dynamiques d'une organisation, et sur le concept d'ambiguïté, d'attention et du mécanisme cognitif associé à ce qui motive les raisons (motivated reasoning). Au sein des véritables institutions, le côté persuasif (ou en tout cas pertinent d'un point de vue utilité du rapport produit) émane non seulement des éléments démontrés mais de la pression, du contexte interne mais aussi de son apport au bon moment. Un rapport venant valoriser une idée reçue familière ou l'attente en matière d'évolution ("pet issue") peut grandir et être porté parce qu'il adhère complètement à une urgence ou au souhait prioritaire : ceci n'en fait pas pour autant l'analyse par essence la plus précise d'un système à risque. A contrario, un rapport analytiquement précis quant à cet état du risque pourrait tomber aux oubliettes s'il ne vient pas au moment propice, là où l'urgence à répondre s'en trouve lointaine.
La subjectivité devient donc un challenge de premier plan lors d'une méthodologie comme celle de Kanita : La mise en condition opérationnelle permet d'illustrer la corrélation mais aucun cas d'évaluation ne repose sur le rapport "vainqueur en vrai". Cette pertinence pratique éclaire fortement et aide mais elle n'engendre pas un indicateur de la "qualité d'analyse pure". Conclure sur ce simple biais mènerait le Kanita Framework à son échec. Ainsi, ce qui survient sur un véritable rapport opérationnel se trouve juste au carrefour de tous ces faisceaux pris en compte de sorte que le système retienne ce signal comme une clé supplémentaire, tout au plus, qu'il ne doit laisser prévaloir de façon magistrale lors d'une évaluation complète.
Aussi le Framework ne veut pas évincer l'angle subjectif, mais s'attelle de plus en plus au sein de Kanita à l'étudier autour et de par la dynamique créée via :
- Les résultats d'exécution pris aux modèles de références sur la thématique ("Golden Set")
- Au sein de chaque version itérée en évaluation
- Sur une perspective englobant les différents profils d'évaluateurs et de leurs taux d'harmonie croisés
- En imposant systématiquement de briser les points de repères connus (ex: classement dans la pile à évaluer)
- Et via cette dynamique ciblée (monitoring) sur les conséquences en cycle réel en bout de chaîne d'évaluation (pour observer le contexte décisionnel sans en conclure une fin en soi immédiate).
La démarche qui en découle n'aboutit pas à forger une objectivité incontestable à tout jamais, cela reviendrait à nier le défi évoqué à travers toutes ces phases. L'enjeu prône par nature une harmonisation fiable par une approche "consistante face au filtre des multiples perceptions" en demeurant fondamentalement conscient des variations amenées au travers de ces facteurs temporels, internes et cognitifs des divers systèmes opérationnels (c.f biais du « pet issue » ou encore du timing de la mise à disposition non opportune de la décision - « the report may be ignored if the organisation is not yet ready to act on it »).
Fondements
Cette perspective s'appuie sur de multiples champs disciplinaires. Chacun d'eux apporte un éclairage différent permettant la structuration des approches à la validation qu'exigent les évaluations en sortie d'un modèle pour les systèmes d'aides misant sur l'incertitude dans l'espace formel de la décision.
Évaluation des LLM
À propos du domaine Cette approche tente de synthétiser les moyens en amont de scruter l'acuité et l'assurance avec lesquelles est élaboré le rendu du modèle : cela va porter sur la capacité des performances des biais, le chemin de fond derrière lequel l'analyse a abouti en s'adaptant à cette nouvelle ère de validation : non plus de s'orienter sur un simple QCM certifié par une masse standardisée d'évaluations qui a d'ores et déjà été remplacée par les phases via les paires couplées associant LLM-As-A-Judge (le modèle jugeant sa condition sur la matrice).
Voix et sources associées sur le concept de l'évaluation du modèle en conditions structurantes :
- OpenAI : pour l'incorporation majeure à s'adapter vers l'expérience de la perception humaine et de s'abstraire dans l'évaluation du Pairwise
- Anthropic : En portant son fond de structure au fil de ses propres méthodologies de vérification de consistance pour les rendus du LLM.
- LMSYS & le Lmsys-arena ou par la structure ChatBot-Arena (Zheng et al.) quant à l'influence fondatrice imposée par la nature "As-a-Judge" (Un LLM venant vérifier l'évaluation)
- L'approche fondamentale fixée sous la tutelle HELM (Université de Stanford).
Recherche d'Information (Information Retrieval)
À propos du domaine Ici la focale opère autour de la compréhension de "trouver/sourcer/pondérer" au coeur des masses massives : extraire de l'importance pour servir une situation depuis un grand nombre d'inconnues. Ici une analyse ou le succès n'en devient un que parce qu'elle vient servir une attente précise par utilité/pertinence pour l'acte au lieu de chercher "L'Ensemble Vérifié".
Voix et sources associées sur le concept de traitement et la pertinence du flux (Retrieval Context) :
- Les conférences TREC (Text REtrieval Conference) ayant fait office de pionnier posant les fondements de ce niveau et les matrices sur les validations/les seuils d'utilité requises pour aboutir au choix
- Gerard Salton pour tout l'héritage ayant apporté à l'espace de ce tri sélectif fondé par approche systémique
- Stephen Robertson via sa mise à profit de l'approche et modélisation en probabilité sur ces filtres et extractions dans les ensembles liés au contenu (Ex. Algorithme de recherche par mots et probabilité de corrélation par les poids associés tel que via BM25)
Science de la Décision (Decision Science)
À propos du domaine C'est avec ce courant qu'est compris tout ce prisme du comportement "Humain vs Action Opérationnelle" : un constat qu'elle ne porte point que sur des actes construits purement autour du rationnel absolu. En abordant la pression temporelle et cette frontière complexe posée par les limitations en jeu sur nos perceptions cognitives pour valider le signal, il s'agit alors de mettre en valeur les nuances à travers ces conditions de prise d'acte.
Voix et sources associées sur le concept traitant l'approche comportement/facteur temporel devant aboutir au "Mouvement"/Décision
- Herbert Simon et les enseignements majeurs autour du contexte face aux pressions ("Bounded rationality" & le concept de finalité fixant que la demande a la portée de ne demander parfois non point "L'Optimum" sinon "l'adéquat face aux nécessités" via l'idée de Satisficing)
- Daniel Kahneman & Amos Tversky ou cette dynamique sur laquelle repose chaque pan fondamental de nos biais devant l'inconnue sans réponses immédiates et avérées
- L'apport complémentaire d'un Gerd Gigerenzer en validant via ses recherches cet intérêt parfois crucial lié aux choix heuristiques qui ont le mérite de s'avérer agiles pour soutenir ce contexte où opère une action sous doutes.
Risque et Gouvernance (Risk and Governance)
À propos du domaine Cet ensemble apporte l'angle qui opère lorsqu'une dimension "Structuration d'entreprise et Rigueur Associée" entre en scène. Il n'est en fait pas ici lié aux notions intrinsèquement légales/directives mais il va se placer directement en apportant une méthode aux organisations visées (souvent les larges corporations soumises au champ régulé par la législation comme point de départ inéluctable) de s'arrimer de cadres et garde-fous pour assurer l'architecture du partage des responsabilités : l'exactitude des rôles face aux actions pour aboutir et rendre compte. Il s'agit en fin de processus avec ces garde-fous que "Le bon signalement soit placé face aux ressources possédant les bons niveaux devant le prendre en charge en pleine propriété avec les droits de faire remonter".
Voix et sources associées à travers cet écosystème en matière de structure, gestion de risques avérés et du partage autour des enjeux posés pour les groupes face aux défis techniques/informations ou opérationnels associés :
- Le framework émanant d'ISACA connu sous son entité COBIT. Cet environnement cadre des logistiques strictes face aux décisions et aux buts en gardant le cap des responsabilités/degrés de contrôles (Tels EDM/APO/BAI etc..).
- CGEIT body of knowledge: porte sur le rôle indispensable visant l'intégration entre ces buts finaux/livrables vers les instances du groupe et leur contrôle devant les facteurs incertitudes/risques au jour le jour via les flux et équipes allouées par système
- ISO 31000 : Sur l'aspect strict sur les guides portant en la gestion de toute approche du risque survenant à conditionner l'état et l'organisation sans visibilité formelle de réponse claire face aux doutes.
- Législation (ex EU AI ACT) instaurant dès la base la volonté manifeste de diriger ces conditions et devoirs réglementaires en imposant qu'ils aient force à se transposer d'exigences et d'orientations directement autour des garanties structurelles comme "Devoir d'exigence (sur la chaîne et les flux) / Gouvernance au sein d'un développement / Audits et Traçabilité (qui doivent être intégrés comme vecteurs obligatoires en bout de course pour ces niveaux touchant l'exigence au rang critique (High-Rights level)".
Pris globalement, l'assemblage conceptuel issu de toute l'arborescence provenant de ces champs disciplinaires justifie et légitime la démarche qui fait qu'au lieu "de jauger si les termes rapportés par l'IA ont été bien rédigés", le focus prend le tournant pour affirmer qu'elle se destine à répondre si au final un système IA agissant sous environnement non-maîtrisé est calibré pour diriger l'assistance opérationnellement pertinente et indispensable à l'organisation ou si son usage sous cette approche restera inapproprié et faiseur d'illusion face aux prises d'actes pour la sécurité comme la gouvernance.
Limites et Travaux Futurs
Ce cadre d'évaluation représente un premier pas vers la formalisation d'un système structuré pour les assistants ayant la visée décisionnelle face à cette incertitude inévitable. Malgré cette volonté affichée, cette première étape fait cependant l'objet de points notables sur ses propres faiblesses temporaires et assumées qui l'incluent par la même à s'intégrer sur cette projection "itérative".
La toute première limite repose explicitement au regard des instances du système vis-à-vis des décisions rendues qu'en l'absence même de preuve vérité absolue : Il doit opérer avec comme axe intrinsèque "le choix/validation structurée du biais cognitif associé et assumé " (A défaut d'une "seule source vérité irréfutable - Truth"). Par logique les recours pris dans les comparatifs par "Pairwise" / de références figées aux comparatifs par les ensembles limités fixés via accord d'évaluation ne s'y écartent des approches par de pures et nettes règles absolues objectives.
Parallèlement l'étude est fondée sous le seuil dit des principes "heuristiques" car il découle pour preuve par nature des approches évoquées juste au préalable par une réflexion issue par l'observation pragmatique. Ce recul actuel des méthodes nécessite pour ces cadres précis d'évaluation encore un manque d'avancée concrète "Long-Scale" ou longitudinale posée sous de grandes matrices temporelles. L'approche est ancrée, l'état reste encore conditionné face au spectre des expérimentations dans un laps temporel plus avancé et éprouvé pour assoir son degré final de confirmation validée "en long format".
Le cadre et les perspectives mises ici en avant demeurent fixés : les cas en phase pour son évaluation (tel "DSI" ou "Executive au groupe central") pourront paraître s'écarter s'ils doivent s'appliquer au champ d'étude posé aux approches opérationnelles spécifiques se dédiant purement, sans s'associer avec le prisme "Executive Gouvernance Centrale,". Elles feront alors sans équivoque état devant y devoir soumettre plus qu'un aménagement de principe (une refonte dans un écosystème de matrice ad-hoc).
Il réside toujours cette complexe relation de fond posée vis à vis de son aptitude par la discipline à assurer avec justesse de cette balance face à l'Incertitude / à contrario du Signal et sa pertinence à l'acte. Une question amenée vers ce ratio cherchant non pas la mesure chiffrée pure et absolue, celle de la qualification fine du "soutien justifié vis à vis d'un contexte de pression", qu'il doit adresser vers l'acte d'en valider "utile pour le passage concret". Et ainsi un recours sur les métriques avec une marge quantifiée sera sur ce champ le parcours logique qui trouvera sans aucun doute de formels axes supplémentaires à amener dans ce registre.
Travaux Futurs
Le point convergent vise en une métamorphose itérative d'un modèle encore à l'état sous validation pour qu'il devienne par principe intégré dans son concept de continuité cyclique : La méthode d'évaluation de ce Kanita.
La suite orientée vise à consolider :
- La prise en vue "Évaluateur" vers ses métriques & de repères d'intégration par validation (Benchmarking/Calibration humain vs Modèle de la Machine et Jugement croisés/Accordés sur multiples vagues )
- Focus de la direction sur les paramètres pris au titre "Modèle LLM à sa fonction Juge-Rapporteur/Analyste : LLM as-a-judge" par amélioration continue du guide ou "prompt d'amorces de base sur ces filtres visant par ces règles structurelles/logiques son taux à juger objectivement.
- Ajout croissant de cette liste étamine & des Datas Références sous l'axe "Cas en Or de Tests / Golden Sets " et support des références.
- L'étude dédiée (pour formaliser d'indicateurs "proxy" et non l'implicite/compris mais sous des valeurs) par apports métriques des catégories de la discipline et utilité visée.
- Du côté intrinsèque : S'imposer vers cette piste cherchant l'optimisation visant au cœur par la logique distillée de s'écarter des gigantesques modèles "non qualifiés à une spécialisation de ces tâches uniques" (En trouvant le profil vers de petits Modèles de type Mistral Fine-Tuné dédiés sous ces règles "Gouvernance Triage" exclusives / optimisation).
- Une chaîne avec cette constance "Amélioration Par Cycles du Prompts : Conception - Résultat Analysé => Refonte prompt/Retrieved Rules) " orientée suite au jugement opéré : L'axe Itératif continu en boucle.
L'orientation fixée, celle sur laquelle s'adosse directement tout ce long parcours et effort de tests, c'est finalement celle consistant : à faire de cet assemblage **Ce Bouclier Fermé Continu Itératif d'Évaluations" (Closed-loop evaluation) où des constats rendus sous les validations s'infiltrent pour à nouveau devenir l'origine du Modèle de comparaison dans une nouvelle génération d'acuité.
Conclusion
Cette perception décrète donc d'entamer la transition pour comprendre que l'évaluation visée ne concerne pas "ce texte que va présenter l'IA", mais devient la mesure cherchant d'apprécier la pertinence de cette Capacité apportée d'une structuration afin de permettre la décision dans des états d'Incertitudes majeurs constatés.
Ce récit l'opère dans cette régularité affirmée :
- Un système gouvernant l'organisation d'entreprise au monde concret évolue sous contrainte avec de la place par les données imparfaites / Temps conditionnant à agir/ et biais de priorités internes
- Ces paramètres font "qu'être exhaustif, exact" s'évince fondamentalement face au contexte. Ces règles s'avèrent de facto "inadaptées à évaluer en l'état un système de Triage"
- De ces principes l'ultime intérêt ne vaut : Que s'il y' a rendu à disposition ce : Signal avec une visée claire et un taux de confiance calibré face au choix/acte sans oublier de poser ce retour sur le seuil organisationnel et sa composante responsable pour assumer cette décision
Ce qui, au moment final, aboutit à se formaliser du mariage sous les angles mis :
- L'évaluation orientée (par cette méthode de "comparaison Pairwise vis à vis d'utilité ")
- Orientée des dimensions "Structures fondées par règles en gestion de science, gouvernance de ces instances par principe COBIT
- Une admission au cœur : ne point ignorer Le filtre sous la notion humaine Subjectivité en admettant explicitement que ce dernier, par la conjoncture et acceptation "uptake vs Qualité au temps T" en fera l'ultime échec ou gain vers sa mise effective menant au point de l'acte et l'utilité validée dans l'écosystème .
Et ceci n'en sera par extension que cette "Amorce originelle d'un grand ensemble par principe Initial" en utilisant ses rendus de manière itérative jusqu'à concevoir "Ce Moteur de flux évaluatif par cercle" via LLM (Gemini Mistral etc...) sur langsmith avec ces notes générées pour consolider les promps futurs.
Et d'apporter cette conviction à ce rôle alloué au Kanita de prendre sa structure comme un élément placé "Triage des signaux faibles avec calibration des doutes face au COBIT via une gouvernance préalable".
Toute cette approche nous mène non plus sur le principe vis-à-vis qu'elle retire l'Incertitude d'elle-même, chose qu'elle ne pourrait faire. Elle aboutit au constat majeur du filtre amenant à conclure Qu'elle la convertit avec ces actions et biais vers "Un Signal Actionnable pour aboutir".
Son ambition et but ne recherche plus à tendre sur Analyse sans failles (une notion parfaite).
"Il s'agit donc de fournir ce précis Signal apte à aboutir sous le meilleur échelon, doté du paramétrage évaluatif de taux de certitudes, calibré consciemment des imperfections et doutes via ses données."
Note : Cet article a été traduit de l'anglais à l'aide d'une intelligence artificielle.