
Evaluating AI for Decision-Making Under Uncertainty
A perspective on how AI outputs should be evaluated in governance contexts, arguing for decision-centric evaluation grounded in uncertainty, bounded rationality and enterprise governance principles.
Decision-Centric LLM Evaluation under Uncertainty
Most approaches to evaluating AI assume that the goal is to produce correct, complete, and well-formed text. This article argues that such assumptions break down in real-world governance contexts. When decisions must be made under uncertainty, with incomplete and noisy data, the relevant question is not whether an output is perfect, but whether it leads to the right decision at the right level. This perspective outlines an alternative: a decision-centric approach to AI evaluation grounded in uncertainty, bounded rationality, and enterprise governance.
Kanita Perspective
AI evaluation is often framed around correctness, completeness, and linguistic quality. This framing works well for tasks such as summarization, Q&A, or content generation. It becomes insufficient, however, in the context Kanita (www.kanita.se) operates in: governance, risk, and executive decision-making under uncertainty and time pressure.
Kanita produces governance triage reports from incomplete, noisy, and often ambiguous data. In its most constrained form, the system may rely solely on publicly available information derived from a single URL. This constitutes a deliberately weak signal environment, where data quality is inherently limited and uneven.
The underlying hypothesis is not that AI will produce fully correct or exhaustive analyses, but that decision-makers often benefit from early, imperfect signals rather than delayed, comprehensive reports. The objective is therefore not analytical completeness, but the transformation of weak and fragmented inputs into structured, decision-relevant guidance.
At the core of the Kanita approach is the triage wedge:
- ALLOW — continue within current governance
- FREEZE — pause until ownership and risk are clarified
- FORMAL DECISION REQUIRED — escalate to executive level
This structure reduces ambiguity into actionable categories and aligns urgency with the appropriate organizational level. While richer internal and structured data sources can significantly improve output quality, increased informational completeness does not necessarily lead to better decisions. In high-uncertainty environments, clarity of signal often outweighs completeness of analysis.
This perspective aligns with established concepts such as VUCA (Volatility, Uncertainty, Complexity, Ambiguity) and decision-making under uncertainty, where the goal is not to eliminate uncertainty but to act effectively within it.
From Text Quality to Decision Signal
Conventional evaluation frameworks for language models—including benchmark suites such as HELM (Holistic Evaluation of Language Models) and related approaches—emphasize dimensions such as accuracy, calibration, robustness, and linguistic quality. These frameworks are appropriate when ground truth is well-defined or when outputs can be evaluated against stable reference answers.
In governance and risk contexts, however, such reference points are often unavailable or fundamentally ambiguous. The question is not whether a report is “correct” in an absolute sense, but whether it supports appropriate decision-making given incomplete information.
Kanita therefore reframes evaluation around three core questions: whether the output produces an appropriate decision signal, whether escalation is placed at the correct organizational level, and whether the most relevant risks are surfaced with sufficient clarity to enable action.
The unit of evaluation is thus not the text itself, but its functional impact on decision-making.
This perspective synthesizes insights from multiple research domains: LLM evaluation (pairwise comparison and model-based judging), information retrieval (relevance over completeness), and decision science (bounded rationality and satisficing). Together, these fields suggest that usefulness under uncertainty is a more appropriate evaluation target than textual fidelity.
Operating Under Uncertainty
Kanita’s context is defined by three structural constraints: incomplete and noisy data, high-stakes decision environments, and limited time for analysis. These are not temporary limitations—they are intrinsic properties of real-world governance and risk.
This has two important implications.
First, it makes traditional notions of "correctness" insufficient. When data is partial, ambiguous, or weakly grounded, there is often no stable ground truth against which outputs can be evaluated. Any attempt to optimize for perfect accuracy in such a setting will either lead to false precision or paralysis.
Second, it shifts the problem from analysis to decision-making under constraint. This aligns with established principles in decision science:
- Bounded rationality (Herbert Simon) — decisions are made under constraints of time, information, and cognitive capacity
- Satisficing — the objective is not optimal decisions, but sufficiently good decisions that can be acted upon
The relevance of these concepts is direct. If decision-makers operate under bounded rationality, then evaluation frameworks must reflect the same constraints. Outputs should not be judged by how complete or precise they are in absolute terms, but by how effectively they support action within those constraints.
This leads to a different definition of what "good" means.
A good output is not one that eliminates uncertainty, but one that:
- structures uncertainty into a clear decision signal
- places that signal at an appropriate level of escalation
- enables timely action without overextending the underlying evidence
In other words, quality is defined by decision adequacy under uncertainty, not analytical completeness or textual correctness.
Accordingly, Kanita evaluates outputs based on their ability to produce usable, correctly calibrated decision signals from imperfect data.
What “Good” Looks Like
Defining what constitutes a “good” report in this context is non-trivial. Unlike tasks with clear ground truth, governance triage operates under ambiguity, partial information, and competing interpretations. As a result, the criteria below should not be interpreted as definitive or exhaustive, but as derived heuristics grounded in the constraints and theoretical foundations outlined earlier.
Specifically, they follow from:
- bounded rationality (decisions under limited information and time)
- satisficing (preference for actionable adequacy over optimal completeness)
- relevance-based evaluation (usefulness over absolute correctness)
From this perspective, a “good” report is one that appears to satisfy several overlapping conditions.
First, it should assign a reasonable triage category. Under uncertainty, exact classification is often unattainable; however, the report should position the issue within a plausible decision band (e.g., not materially under- or over-escalating risk). This reflects satisficing rather than precise optimization.
Second, it should place the decision at an appropriate organizational level. This follows from governance theory (e.g., COSO ERM), where the quality of a decision is partly determined by whether it is owned at the correct level of accountability.
Third, it should identify relevant governance and risk themes. Drawing on information retrieval principles, the goal is not exhaustive coverage, but capturing the most decision-relevant signals (e.g., regulatory exposure, accountability gaps, traceability issues).
Fourth, it should enable concrete discussion and action. In line with bounded rationality, outputs must reduce cognitive load rather than increase it. A report that is analytically rich but operationally ambiguous is of limited value.
Fifth, it should demonstrate appropriate handling of uncertainty. This includes making assumptions explicit, avoiding unwarranted precision, and distinguishing between observation and inference. This aligns with epistemic calibration rather than factual completeness.
These dimensions are interdependent rather than independent metrics, and trade-offs are expected. In particular, two failure modes are consistently observed:
- Overconfidence based on weak signals, where the report overstates certainty or escalates without sufficient grounding
- Excessive caution, where uncertainty is handled so conservatively that no actionable signal remains
A “good” output does not eliminate these tensions, but balances them. It is sufficiently structured to support action, while remaining appropriately calibrated to the limits of the underlying data.
In this sense, quality is best understood not as correctness, but as decision adequacy under uncertainty.
How Evaluation Works (Initial Method)
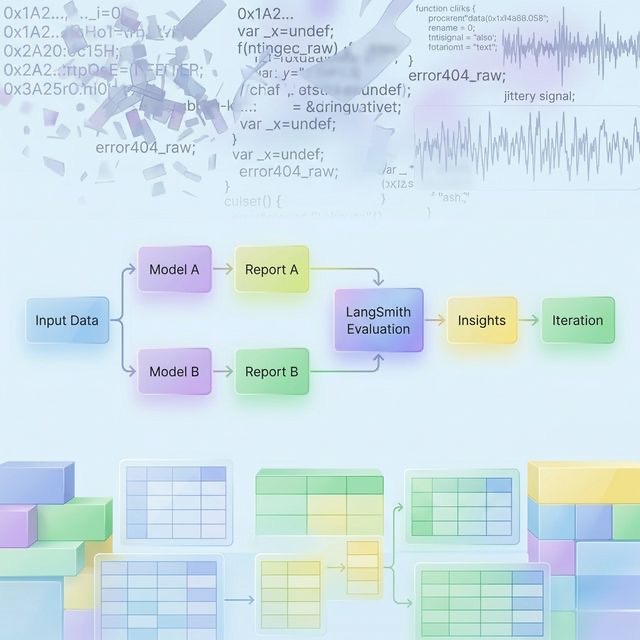
The current implementation represents an initial method for evaluating governance triage outputs across different models and configurations.
Multiple reports are generated from the same underlying data using different models (e.g., Google Gemini, Mistral) and model sizes. This creates a controlled comparison set where variation is driven by model behavior rather than input differences.
The resulting outputs are evaluated in LangSmith using a combination of:
- Comparative evaluation (pairwise)
- Structured dimension-based scoring
This setup enables both ranking (which report is better) and diagnostic insight (why it is better).
Comparative evaluation
Reports are assessed pairwise. The central question is:
Which report better supports executive decision-making?
Pairwise comparison is empirically more robust than absolute scoring in contexts characterized by ambiguity and incomplete ground truth.
Structured dimensions
Each report is also assessed across a defined set of dimensions:
- triage correctness
- decision-level accuracy
- risk relevance
- decision usefulness
- uncertainty discipline
- claim discipline (avoidance of unsupported conclusions)
These dimensions are measured using ordinal scales to preserve interpretability and reduce false precision.
From a governance perspective, these dimensions can also be understood through a COBIT lens:
- Triage correctness → aligns with ensuring that risks are properly evaluated and that appropriate control actions are triggered (risk optimization)
- Decision-level accuracy → reflects correct allocation of decision rights and accountability (governance vs management responsibilities)
- Risk relevance → corresponds to identifying and prioritizing enterprise risks that impact value delivery
- Decision usefulness → supports value creation by enabling actionable and timely decisions
- Uncertainty discipline → relates to maintaining appropriate levels of assurance and avoiding false precision in control and reporting
- Claim discipline → aligns with integrity and reliability of information used in governance and decision-making
This mapping reinforces that the evaluation dimensions are not arbitrary, but consistent with established principles in IT governance and enterprise risk management.
More specifically, the framework can be interpreted as a lightweight, decision-centric operationalization of COBIT principles under uncertainty. In particular:
- EDM (Evaluate, Direct, Monitor) → reflected in triage correctness and decision-level accuracy, ensuring that the right issues are escalated and governed at the appropriate level
- APO (Align, Plan, Organize) → reflected in risk relevance and decision usefulness, linking identified risks to actionable organizational responses
- BAI (Build, Acquire, Implement) → indirectly supported through uncertainty and claim discipline, ensuring that decisions entering delivery pipelines are appropriately qualified and grounded
This interpretation positions the framework not as an alternative to established governance models, but as a complementary layer focused on early-stage signal structuring and decision support.
How the dimensions are assessed
Each dimension is evaluated using observable signals in the output rather than subjective impressions alone.
Triage correctness
- Does the recommended action (ALLOW / FREEZE / FORMAL DECISION) align with the described risk level?
- Red flags: under-escalation of safety/regulatory issues, or over-escalation of minor concerns
Decision-level accuracy
- Is the issue placed at the appropriate organizational level (team vs CIO vs executive)?
- Signal: alignment between risk scope and decision authority
Risk relevance
- Are the most material governance risks identified?
- Signal: presence of key themes (regulatory, accountability, traceability, third-party risk)
Decision usefulness
- Can a decision-maker act on this immediately?
- Signal: clarity of next step, absence of ambiguity, explicit escalation logic
Uncertainty discipline
- Does the report appropriately qualify assumptions?
- Signal: distinction between observed facts, inferred conclusions, and unknowns
Claim discipline
- Are claims proportionate to available evidence?
- Signal: absence of unsupported or overly specific assertions
Example matrix: Good vs Poor outputs
| Dimension | Good example | Poor example |
|---|---|---|
| Triage correctness | Escalates AI in safety systems to FORMAL DECISION due to regulatory exposure | Classifies same issue as ALLOW with vague justification |
| Decision-level accuracy | Assigns cross-functional governance issue to CIO level | Leaves systemic governance issue at team level |
| Risk relevance | Identifies AI Act, traceability, and QA gaps | Focuses only on general "AI is important" statements |
| Decision usefulness | Clearly states "pause deployment until validation process is defined" | Provides analysis but no clear recommendation |
| Uncertainty discipline | States assumptions and highlights unknowns explicitly | Presents inferred claims as established facts |
| Claim discipline | Uses cautious language for inferred risks | Makes specific claims about systems or processes without evidence |
This initial method is designed to be iterative. Evaluation outputs are not only used to compare models, but also to inform prompt design, model selection, and future system improvements.
Anchoring Subjectivity
This is likely the most difficult part of the framework. In practice, the value of a report is not determined only by its internal quality, but by what it does in a real organizational setting. A report may be judged “good” because it is analytically well calibrated, or because it helps a decision-maker surface a neglected but important issue. But it may also be judged “good” for less defensible reasons: because it supports a pre-existing agenda, amplifies a favored concern, or arrives at a moment when the organization is unusually receptive to that issue.
Core idea:
A report can be effective in practice for reasons other than being analytically good.
This creates a critical distinction between three related but different concepts:
- Analytical quality — how well the report reflects available evidence and handles uncertainty
- Organizational uptake — whether the report is accepted, discussed, or acted upon
- Decision impact — whether the report leads to meaningful or correct decisions over time
These do not always align. A report may achieve strong uptake but low analytical quality (e.g., by reinforcing a “pet issue”), or high analytical quality but low uptake (e.g., due to poor timing or organizational readiness).
For that reason, Kanita treats subjectivity not as noise that can simply be removed, but as part of the phenomenon being studied. The practical test is, in part, "the proof of the pudding": a limited set of real cases is being collected in order to observe how outputs are received, used, and interpreted in actual decision contexts.
This perspective is consistent with research on uncertainty and ecological rationality, especially the work of Gerd Gigerenzer. A central insight in that tradition is that judgments should not be evaluated only in abstraction, but in relation to the environments in which they are used. In uncertain environments, simple heuristics can outperform more complex models when they are well matched to the structure of the task. By extension, the usefulness of a governance report cannot be assessed purely by textual properties; it must be assessed relative to the organizational context, the timing of the decision, and the type of action the report is meant to support.
This also connects to organizational research on ambiguity, attention, and motivated reasoning. In real institutions, what is considered persuasive or useful is shaped not only by evidence, but also by incentives, issue salience, and timing. A report that elevates a "pet issue" may gain traction because it resonates with current political priorities, not because it is the best representation of the underlying risk. Conversely, a better-calibrated report may be ignored if the organization is not yet ready to act on it.
These dynamics create an important methodological challenge: evaluation cannot rely only on whether a report "wins" in practice. Practical uptake is informative, but it is not equivalent to analytical quality. Real-world use should therefore be treated as one signal among several, not as the sole arbiter of quality.
Rather than attempting to eliminate subjectivity, Kanita seeks to constrain and study it through:
- curated reference cases ("golden set")
- repeated evaluation runs
- agreement measurement across evaluators
- randomized comparison ordering to reduce bias
- limited observation of real-world uptake and use
The objective is not objectivity in an absolute sense, but consistency and reliability under subjective judgment, while remaining attentive to the fact that judgment itself is shaped by uncertainty, organizational context, and timing. A report that elevates a "pet issue" may gain traction because it resonates with current political priorities, not because it is the best representation of the underlying risk. Conversely, a better-calibrated report may be ignored if the organization is not yet ready to act on it.
These dynamics create an important methodological challenge: evaluation cannot rely only on whether a report "wins" in practice. Practical uptake is informative, but it is not equivalent to analytical quality. Real-world use should therefore be treated as one signal among several, not as the sole arbiter of quality.
Rather than attempting to eliminate subjectivity, Kanita seeks to constrain and study it through:
- curated reference cases ("golden set")
- repeated evaluation runs
- agreement measurement across evaluators
- randomized comparison ordering to reduce bias
- limited observation of real-world uptake and use
The objective is not objectivity in an absolute sense, but consistency and reliability under subjective judgment, while remaining attentive to the fact that judgment itself is shaped by uncertainty, organizational context, and timing.
Foundations
This perspective draws on multiple established fields. Each contributes a different lens for understanding how to evaluate AI-generated outputs in decision-making contexts.
LLM Evaluation
What the field is about
LLM evaluation focuses on assessing the performance of language models across dimensions such as accuracy, reasoning, robustness, and alignment with human preferences. As models have become more capable, evaluation has shifted from static benchmarks toward more dynamic methods such as pairwise comparison and model-based judging.
Key voices and contributions
- OpenAI (e.g., GPT-4 report): introduced large-scale use of human preference and pairwise evaluation
- Anthropic: emphasized structured evaluation, alignment, and consistency
- LMSYS (Zheng et al.): demonstrated LLM-as-a-judge and comparative evaluation methods
- Stanford HELM project: holistic evaluation across multiple dimensions and scenarios
Information Retrieval
What the field is about
Information retrieval studies how to find and rank relevant information from large, noisy datasets. Evaluation focuses not on absolute correctness, but on relevance—whether retrieved information is useful for a given task.
Key voices and contributions
- TREC (Text REtrieval Conference): established relevance-based evaluation standards
- Gerard Salton: foundational work on vector space models and ranking
- Stephen Robertson: probabilistic retrieval models (e.g., BM25)
Decision Science
What the field is about
Decision science examines how individuals and organizations make choices under constraints such as limited information, time pressure, and cognitive limitations. It challenges the assumption of fully rational decision-making.
Key voices and contributions
- Herbert Simon: bounded rationality and satisficing
- Daniel Kahneman & Amos Tversky: heuristics, biases, and decision-making under uncertainty
- Gerd Gigerenzer: ecological rationality and adaptive heuristics
Risk and Governance
What the field is about
Risk and governance frameworks define how organizations structure decision rights, accountability, control mechanisms, and risk management in complex environments. In this context, governance is not only about compliance, but about ensuring that decisions are made at the right level, with the right information, and with clear ownership.
Key voices and contributions
- COBIT (ISACA): provides a comprehensive framework for governance and management of enterprise IT, emphasizing alignment between business goals, control objectives, and decision rights
- CGEIT body of knowledge: focuses on governance of enterprise IT, including value delivery, risk optimization, and resource management
- ISO 31000: principles and guidelines for risk management under uncertainty
- EU AI Act: emerging European regulatory framework for high-risk AI systems, emphasizing traceability, accountability, and governance
Together, these fields support a shift from evaluating text outputs to evaluating decision-support systems operating under uncertainty.
Limitations and Future Work
This framework represents an initial attempt to formalize evaluation of decision-support systems under uncertainty. As such, it has several limitations.
First, the framework relies on structured subjective judgment rather than objective ground truth. While mechanisms such as pairwise comparison, agreement measurement, and reference cases reduce arbitrariness, they do not eliminate it. Evaluation outcomes remain sensitive to rubric design and evaluator assumptions.
Second, the current criteria are heuristic and inductive. They are derived from theory (decision science, information retrieval, governance) and early empirical observations, but they have not yet been validated through large-scale or longitudinal studies.
Third, the framework assumes a relatively consistent decision context (CIO / executive governance). Its applicability to other domains or decision environments may require adaptation.
Fourth, the balance between uncertainty calibration and actionability remains difficult to measure precisely. Over time, more formal proxies and metrics may be required to assess this trade-off more reliably.
Future Work
Future development will focus on transforming this conceptual framework into a continuously improving evaluation system.
Key directions include:
-
Evaluator calibration and benchmarking
Systematic measurement of agreement between human evaluators and LLM-based judges, including stability across repeated runs. -
LLM-as-a-judge development
Refinement of evaluation prompts and schemas to improve consistency, reduce bias, and enable scalable comparative evaluation. -
Dataset expansion ("golden set")
Construction of a larger and more diverse reference dataset to anchor evaluation and support statistical analysis. -
Metric formalization
Development of more explicit and testable proxies for dimensions such as decision usefulness, uncertainty discipline, and overclaim rates. -
Model optimization
Use of evaluation signals to support fine-tuning or distillation of smaller, more efficient models optimized for governance triage tasks. -
Prompt and system design iteration
Continuous refinement of prompts, pipelines, and retrieval strategies based on observed evaluation outcomes.
The long-term objective is to evolve this into a closed-loop evaluation and improvement system, where outputs are continuously assessed, compared, and used to improve both models and evaluation methods.
Conclusion
This perspective reframes AI evaluation from a question of textual quality to a question of decision support under uncertainty.
Across the document, a consistent position emerges:
- Real-world governance operates with incomplete data, time pressure, and competing interpretations.
- Under these conditions, correctness and completeness are insufficient evaluation targets.
- What matters is whether outputs produce appropriately calibrated, actionable decision signals.
The proposed approach therefore combines:
- Comparative evaluation (which report is more useful for decision-making)
- Structured dimensions grounded in decision science, information retrieval, and COBIT-aligned governance principles
- Explicit handling of subjectivity, acknowledging the gap between analytical quality, organizational uptake, and decision impact
Practically, this is implemented as an initial method: multiple models (e.g., Gemini, Mistral) generate reports on the same data; outputs are evaluated in LangSmith; results inform model choice, prompt design, and system iteration. The method is intentionally iterative and designed to evolve into a closed-loop evaluation system.
Conceptually, the framework positions Kanita as a layer that operates upstream of formal governance—structuring weak signals into triage decisions that align with COBIT principles (EDM/APO/BAI) while remaining calibrated to uncertainty.
The key implication is not that uncertainty can be removed, but that it can be made actionable.
The goal is not perfect analysis.
It is the right decision signal, at the right level, with calibrated confidence, from imperfect data.