
Att utvärdera AI för beslutsfattande under osäkerhet
Ett perspektiv på hur AI-utdata bör utvärderas i styrningssammanhang, med argument för en beslutscentrerad utvärdering grundad i osäkerhet, begränsad rationalitet och principer för verksamhetsstyrning.
Beslutscentrerad LLM-utvärdering under osäkerhet
De flesta sätt att utvärdera AI utgår från att målet är att producera korrekt, fullständig och välformulerad text. Den här artikeln argumenterar för att sådana antaganden inte håller i verkliga styrningssammanhang. När beslut måste fattas under osäkerhet, med ofullständiga och brusiga data, är den relevanta frågan inte om ett resultat är perfekt, utan om det leder till rätt beslut på rätt nivå. Det här perspektivet beskriver ett alternativ: ett beslutscentrerat sätt att utvärdera AI, grundat i osäkerhet, begränsad rationalitet och principer för verksamhetsstyrning.
Kanitas perspektiv
AI-utvärdering ramas ofta in kring korrekthet, fullständighet och språklig kvalitet. Det fungerar bra för uppgifter som sammanfattning, frågor och svar eller innehållsgenerering. Däremot blir det otillräckligt i den kontext där Kanita (www.kanita.se) verkar: styrning, risk och ledningsbeslut under osäkerhet och tidspress.
Kanita tar fram triagerapporter för styrning baserat på ofullständiga, brusiga och ofta tvetydiga data. I sin mest begränsade form kan systemet enbart luta sig mot publikt tillgänglig information från en enda URL. Det är en medvetet svag signalmiljö, där datakvaliteten i grunden är begränsad och ojämn.
Den underliggande hypotesen är inte att AI kommer att producera helt korrekta eller uttömmande analyser, utan att beslutsfattare ofta har större nytta av tidiga, ofullkomliga signaler än av fördröjda, heltäckande rapporter. Målet är därför inte analytisk fullständighet, utan att omvandla svaga och fragmenterade underlag till strukturerad vägledning som är relevant för beslut.
Kärnan i Kanitas arbetssätt är triageringskilen:
- TILLÅT — fortsätt inom nuvarande styrning
- FRYS — pausa tills ansvar och risk har klargjorts
- FORMELLT BESLUT KRÄVS — eskalera till ledningsnivå
Den här strukturen minskar tvetydighet till handlingsbara kategorier och kopplar brådska till rätt organisatorisk nivå. Rikare interna och strukturerade datakällor kan förstås höja kvaliteten i resultatet avsevärt, men mer fullständig information leder inte nödvändigtvis till bättre beslut. I miljöer med hög osäkerhet väger signalens tydlighet ofta tyngre än analysens fullständighet.
Det här perspektivet ligger i linje med etablerade begrepp som VUCA (volatilitet, osäkerhet, komplexitet, tvetydighet) och beslutsfattande under osäkerhet, där målet inte är att eliminera osäkerhet utan att agera effektivt inom den.
Från textkvalitet till beslutssignal
Traditionella ramverk för utvärdering av språkmodeller — inklusive benchmarks som HELM (Holistic Evaluation of Language Models) och närliggande angreppssätt — betonar dimensioner som träffsäkerhet, kalibrering, robusthet och språklig kvalitet. De här ramverken passar när facit är tydligt definierat eller när resultat kan jämföras mot stabila referenssvar.
I styrnings- och risksammanhang saknas däremot sådana referenspunkter ofta, eller så är de i grunden tvetydiga. Frågan är inte om en rapport är ”korrekt” i absolut mening, utan om den stödjer lämpligt beslutsfattande givet ofullständig information.
Kanita ramar därför in utvärderingen kring tre kärnfrågor: om resultatet ger en rimlig beslutssignal, om eskaleringen hamnar på rätt organisatorisk nivå och om de mest relevanta riskerna lyfts fram med tillräcklig tydlighet för att möjliggöra handling.
Utvärderingsenheten är alltså inte texten i sig, utan dess funktionella påverkan på beslutsfattandet.
Det här perspektivet sammanför insikter från flera forskningsfält: LLM-utvärdering (parvisa jämförelser och modellbaserad bedömning), informationsåtervinning (relevans viktigare än fullständighet) och beslutsvetenskap (begränsad rationalitet och satisfiering). Tillsammans pekar de på att användbarhet under osäkerhet är ett mer relevant utvärderingsmål än textuell trohet.
Att verka under osäkerhet
Kanitas kontext präglas av tre strukturella begränsningar: ofullständiga och brusiga data, beslutsmiljöer med höga insatser och begränsad tid för analys. Det här är inga tillfälliga hinder — det är inneboende egenskaper i verklig styrning och riskhantering.
Det får två viktiga konsekvenser.
För det första räcker inte traditionella föreställningar om "korrekthet". När data är partiella, tvetydiga eller svagt förankrade finns det ofta inget stabilt facit att utvärdera resultaten mot. Försök att optimera för perfekt träffsäkerhet i en sådan miljö leder antingen till skenbar precision eller handlingsförlamning.
För det andra förskjuts problemet från analys till beslutsfattande under begränsningar. Det ligger i linje med etablerade principer inom beslutsvetenskap:
- Begränsad rationalitet (Herbert Simon) — beslut fattas under begränsningar i tid, information och kognitiv kapacitet
- Satisfiering — målet är inte optimala beslut, utan tillräckligt bra beslut som går att agera på
Kopplingen till de här begreppen är direkt. Om beslutsfattare arbetar under begränsad rationalitet måste också utvärderingsramverk spegla samma begränsningar. Resultat bör inte bedömas efter hur fullständiga eller precisa de är i absoluta termer, utan efter hur väl de stödjer handling inom dessa ramar.
Det leder till en annan definition av vad som är "bra".
Ett bra resultat är inte ett som eliminerar osäkerhet, utan ett som:
- strukturerar osäkerhet till en tydlig beslutssignal
- placerar signalen på en lämplig eskaleringsnivå
- möjliggör snabba åtgärder utan att gå längre än underlaget faktiskt bär
Med andra ord definieras kvalitet av beslutsmässig tillräcklighet under osäkerhet, inte av analytisk fullständighet eller textuell korrekthet.
Kanita utvärderar därför resultat utifrån deras förmåga att skapa användbara, rätt kalibrerade beslutssignaler från ofullkomliga data.
Hur ett “bra” resultat ser ut
Att definiera vad som utgör en “bra” rapport i den här kontexten är inte enkelt. Till skillnad från uppgifter med tydligt facit sker styrningstriage under tvetydighet, partiell information och konkurrerande tolkningar. Kriterierna nedan ska därför inte läsas som definitiva eller uttömmande, utan som härledda tumregler förankrade i de begränsningar och teoretiska utgångspunkter som beskrivits tidigare.
Mer konkret följer de av:
- begränsad rationalitet (beslut under begränsad information och tid)
- satisfiering (företräde för handlingsbar tillräcklighet framför optimal fullständighet)
- relevansbaserad utvärdering (användbarhet viktigare än absolut korrekthet)
Ur det här perspektivet är en “bra” rapport en rapport som verkar uppfylla flera överlappande villkor.
För det första bör den tilldela en rimlig triageringskategori. Under osäkerhet går det sällan att nå exakt klassificering, men rapporten bör placera frågan inom ett trovärdigt beslutsintervall, till exempel utan att tydligt under- eller övereskalera risken. Det speglar satisfiering snarare än exakt optimering.
För det andra bör den placera beslutet på en lämplig organisatorisk nivå. Det följer av styrningsteori, till exempel COSO ERM, där kvaliteten i ett beslut delvis avgörs av om det ägs på rätt ansvarsnivå.
För det tredje bör den identifiera relevanta teman inom styrning och risk. Med utgångspunkt i principer från informationsåtervinning är målet inte uttömmande täckning, utan att fånga de signaler som är mest relevanta för beslut, till exempel regulatorisk exponering, ansvarsglapp och spårbarhetsproblem.
För det fjärde bör den möjliggöra konkret diskussion och handling. I linje med begränsad rationalitet måste resultat minska den kognitiva belastningen, inte öka den. En rapport som är analytiskt rik men operativt tvetydig har begränsat värde.
För det femte bör den visa ändamålsenlig hantering av osäkerhet. Det innebär bland annat att antaganden görs tydliga, att omotiverad precision undviks och att observation skiljs från slutsats. Det ligger närmare epistemisk kalibrering än faktisk fullständighet.
De här dimensionerna är beroende av varandra snarare än fristående mått, och avvägningar är att vänta. Särskilt två typer av fel återkommer:
- Överdriven säkerhet baserad på svaga signaler, där rapporten uttrycker större säkerhet eller eskalerar utan tillräcklig grund
- Överdriven försiktighet, där osäkerheten hanteras så defensivt att ingen handlingsbar signal återstår
Ett “bra” resultat eliminerar inte de här spänningarna, men balanserar dem. Det är tillräckligt strukturerat för att stödja handling, samtidigt som det är rimligt kalibrerat utifrån underlagets begränsningar.
I den meningen förstås kvalitet bäst inte som korrekthet, utan som beslutsmässig tillräcklighet under osäkerhet.
Hur utvärderingen fungerar (första metodversionen)
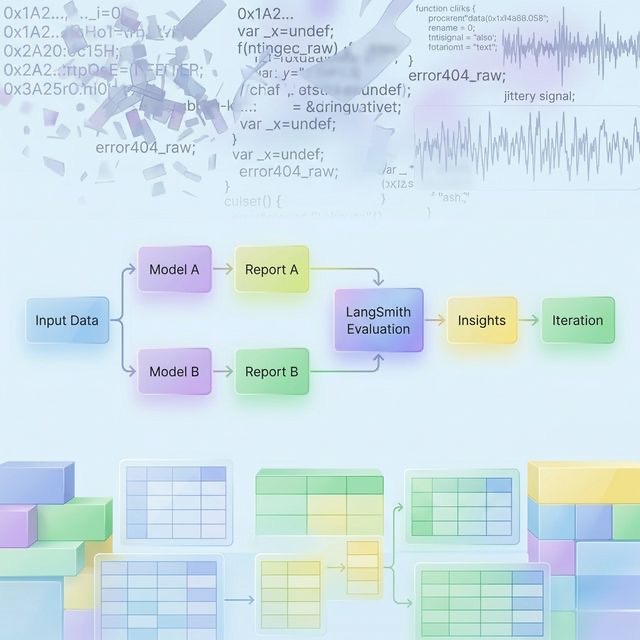
Den nuvarande implementationen är en första metodversion för att utvärdera resultat från styrningstriage mellan olika modeller och konfigurationer.
Flera rapporter genereras från samma underliggande data med olika modeller, till exempel Google Gemini och Mistral, samt olika modellstorlekar. Det skapar en kontrollerad jämförelseuppsättning där variationen drivs av modellbeteende snarare än skillnader i indata.
De framtagna resultaten utvärderas i LangSmith med en kombination av:
- Jämförande utvärdering (parvis)
- Strukturerad bedömning per dimension
Det här upplägget gör det möjligt att både rangordna resultat (vilken rapport som är bättre) och få diagnostisk förståelse för varför den är bättre.
Jämförande utvärdering
Rapporter bedöms parvis. Den centrala frågan är:
Vilken rapport stödjer ledningsbeslut bäst?
Parvisa jämförelser är empiriskt mer robusta än absolut poängsättning i sammanhang som präglas av tvetydighet och avsaknad av tydligt facit.
Strukturerade dimensioner
Varje rapport bedöms också utifrån en definierad uppsättning dimensioner:
- korrekt triagering
- träffsäkerhet i beslutsnivå
- riskrelevans
- användbarhet för beslut
- disciplin i hantering av osäkerhet
- påståendedisciplin (att undvika slutsatser utan stöd)
Dessa dimensioner mäts med ordnade skalor för att bevara tolkningsbarheten och minska skenbar precision.
Ur ett styrningsperspektiv kan dimensionerna också förstås genom ett COBIT-perspektiv:
- Korrekt triagering → ligger i linje med att säkerställa att risker bedöms på rätt sätt och att lämpliga kontrollåtgärder utlöses (riskoptimering)
- Träffsäkerhet i beslutsnivå → speglar korrekt fördelning av beslutanderätt och ansvar (styrning kontra ledning)
- Riskrelevans → motsvarar att identifiera och prioritera verksamhetsrisker som påverkar värdeskapandet
- Användbarhet för beslut → stödjer värdeskapande genom att möjliggöra handlingsbara och snabba beslut
- Disciplin i hantering av osäkerhet → hänger ihop med att upprätthålla rimliga nivåer av säkerhet och undvika skenbar precision i kontroll och rapportering
- Påståendedisciplin → ligger i linje med integritet och tillförlitlighet i den information som används i styrning och beslutsfattande
Den här kopplingen förstärker att utvärderingsdimensionerna inte är godtyckliga, utan förenliga med etablerade principer inom IT-styrning och verksamhetsövergripande riskhantering.
Mer specifikt kan ramverket förstås som en lättviktig, beslutscentrerad operationalisering av COBIT-principer under osäkerhet. Särskilt gäller detta:
- EDM (Evaluate, Direct, Monitor) → speglas i korrekt triagering och träffsäkerhet i beslutsnivå, så att rätt frågor eskaleras och styrs på rätt nivå
- APO (Align, Plan, Organize) → speglas i riskrelevans och användbarhet för beslut, där identifierade risker kopplas till handlingsbara organisatoriska svar
- BAI (Build, Acquire, Implement) → stöds indirekt genom disciplin i osäkerhet och påståenden, så att beslut som förs in i leveransflöden är rimligt kvalificerade och förankrade
Den här tolkningen placerar inte ramverket som ett alternativ till etablerade styrningsmodeller, utan som ett kompletterande lager med fokus på tidig strukturering av signaler och beslutsstöd.
Hur dimensionerna bedöms
Varje dimension utvärderas utifrån observerbara signaler i resultatet, inte enbart subjektiva intryck.
Korrekt triagering
- Stämmer den rekommenderade åtgärden (TILLÅT / FRYS / FORMELLT BESLUT) överens med den beskrivna risknivån?
- Varningssignaler: undereskalering av säkerhets- eller regulatoriska frågor, eller övereskalering av mindre problem
Träffsäkerhet i beslutsnivå
- Har frågan placerats på rätt organisatorisk nivå (team vs CIO vs ledning)?
- Signal: överensstämmelse mellan riskens omfattning och beslutsmandat
Riskrelevans
- Identifieras de mest väsentliga styrningsriskerna?
- Signal: förekomst av nyckelteman (reglering, ansvar, spårbarhet, tredjepartsrisk)
Användbarhet för beslut
- Kan en beslutsfattare agera på detta direkt?
- Signal: tydligt nästa steg, frånvaro av tvetydighet, uttrycklig logik för eskalering
Disciplin i hantering av osäkerhet
- Kvalificerar rapporten sina antaganden på ett rimligt sätt?
- Signal: åtskillnad mellan observerade fakta, dragna slutsatser och okända faktorer
Påståendedisciplin
- Är påståendena proportionerliga i förhållande till tillgängliga bevis?
- Signal: frånvaro av påståenden utan stöd eller överdrivet specifika utsagor
Exempelmatris: Bra respektive svaga resultat
| Dimension | Bra exempel | Svagt exempel |
|---|---|---|
| Korrekt triagering | Eskalerar AI i säkerhetssystem till FORMELLT BESLUT på grund av regulatorisk exponering | Klassar samma fråga som TILLÅT med vag motivering |
| Träffsäkerhet i beslutsnivå | Lägger en tvärfunktionell styrningsfråga på CIO-nivå | Lämnar en systemisk styrningsfråga på teamnivå |
| Riskrelevans | Identifierar AI Act, spårbarhet och brister i kvalitetssäkring | Fokuserar bara på allmänna påståenden om att "AI är viktigt" |
| Användbarhet för beslut | Säger tydligt "pausa driftsättning tills en valideringsprocess är definierad" | Ger analys men ingen tydlig rekommendation |
| Disciplin i osäkerhet | Redovisar antaganden och lyfter okända faktorer tydligt | Presenterar slutsatser som om de vore fastställda fakta |
| Påståendedisciplin | Använder försiktigt språk för härledda risker | Gör specifika påståenden om system eller processer utan underlag |
Den här första metoden är tänkt att vara iterativ. Resultaten från utvärderingen används inte bara för att jämföra modeller, utan också för att informera promptdesign, modellval och framtida förbättringar av systemet.
Att förankra subjektivitet
Det här är sannolikt den svåraste delen av ramverket. I praktiken avgörs värdet av en rapport inte bara av dess interna kvalitet, utan av vad den faktiskt gör i en verklig organisation. En rapport kan bedömas som “bra” för att den är analytiskt väl kalibrerad, eller för att den hjälper en beslutsfattare att få syn på en viktig fråga som tidigare förbisetts. Men den kan också bedömas som “bra” av mindre hållbara skäl: för att den stödjer en redan etablerad agenda, förstärker en favoritfråga eller råkar komma vid en tidpunkt då organisationen är ovanligt mottaglig för just den frågan.
Kärnidé:
En rapport kan fungera väl i praktiken av andra skäl än att den är analytiskt bra.
Det skapar en avgörande skillnad mellan tre närliggande men olika begrepp:
- Analytisk kvalitet — hur väl rapporten speglar tillgängligt underlag och hanterar osäkerhet
- Organisatoriskt genomslag — om rapporten tas emot, diskuteras eller leder till handling
- Beslutspåverkan — om rapporten över tid leder till meningsfulla eller korrekta beslut
Dessa sammanfaller inte alltid. En rapport kan få starkt genomslag men ha låg analytisk kvalitet, till exempel genom att förstärka en “hjärtefråga”, eller ha hög analytisk kvalitet men svagt genomslag, till exempel på grund av dålig tajmning eller låg organisatorisk beredskap.
Av det skälet ser Kanita inte subjektivitet som brus som enkelt kan rensas bort, utan som en del av själva fenomenet som studeras. Det praktiska testet är delvis "the proof of the pudding": ett begränsat antal verkliga fall samlas in för att observera hur resultat tas emot, används och tolkas i faktiska beslutssituationer.
Det här perspektivet ligger i linje med forskning om osäkerhet och ekologisk rationalitet, särskilt arbetet av Gerd Gigerenzer. En central insikt i den traditionen är att omdömen inte bara bör utvärderas i abstraktion, utan i relation till de miljöer där de används. I osäkra miljöer kan enkla tumregler överträffa mer komplexa modeller när de passar uppgiftens struktur väl. På samma sätt kan nyttan av en styrningsrapport inte bedömas enbart utifrån textuella egenskaper; den måste bedömas i relation till organisatorisk kontext, beslutets tajmning och vilken typ av handling rapporten är tänkt att stödja.
Det här knyter också an till organisationsforskning om tvetydighet, uppmärksamhet och motiverat tänkande. I verkliga institutioner formas det som uppfattas som övertygande eller användbart inte bara av underlag, utan också av incitament, frågors synlighet och tajmning. En rapport som lyfter en "hjärtefråga" kan få fäste för att den ligger i linje med aktuella politiska prioriteringar, inte för att den bäst representerar den underliggande risken. Omvänt kan en bättre kalibrerad rapport ignoreras om organisationen ännu inte är redo att agera på den.
De här dynamikerna skapar en viktig metodutmaning: utvärdering kan inte bara bygga på om en rapport "vinner" i praktiken. Praktiskt genomslag är informativt, men det är inte samma sak som analytisk kvalitet. Verklig användning bör därför behandlas som en signal bland flera, inte som den enda domaren av kvalitet.
I stället för att försöka eliminera subjektivitet försöker Kanita begränsa och studera den genom:
- kurerade referensfall ("golden set")
- upprepade utvärderingskörningar
- mätning av samstämmighet mellan utvärderare
- slumpad jämförelseordning för att minska bias
- begränsad observation av faktiskt genomslag och användning
Målet är inte objektivitet i absolut mening, utan konsekvens och tillförlitlighet under subjektiv bedömning, samtidigt som man behåller uppmärksamheten på att själva omdömet formas av osäkerhet, organisatorisk kontext och tajmning. En rapport som lyfter en "hjärtefråga" kan få fäste för att den ligger i linje med aktuella politiska prioriteringar, inte för att den bäst representerar den underliggande risken. Omvänt kan en bättre kalibrerad rapport ignoreras om organisationen ännu inte är redo att agera på den.
De här dynamikerna skapar en viktig metodutmaning: utvärdering kan inte bara bygga på om en rapport "vinner" i praktiken. Praktiskt genomslag är informativt, men det är inte samma sak som analytisk kvalitet. Verklig användning bör därför behandlas som en signal bland flera, inte som den enda domaren av kvalitet.
I stället för att försöka eliminera subjektivitet försöker Kanita begränsa och studera den genom:
- kurerade referensfall ("golden set")
- upprepade utvärderingskörningar
- mätning av samstämmighet mellan utvärderare
- slumpad jämförelseordning för att minska bias
- begränsad observation av faktiskt genomslag och användning
Målet är inte objektivitet i absolut mening, utan konsekvens och tillförlitlighet under subjektiv bedömning, samtidigt som man behåller uppmärksamheten på att själva omdömet formas av osäkerhet, organisatorisk kontext och tajmning.
Teoretiska grunder
Det här perspektivet hämtar stöd från flera etablerade fält. Var och en bidrar med ett eget perspektiv på hur AI-genererade resultat bör utvärderas i beslutsmiljöer.
LLM-utvärdering
Vad fältet handlar om
LLM-utvärdering fokuserar på att bedöma språkmodellers prestation längs dimensioner som träffsäkerhet, resonemangsförmåga, robusthet och anpassning till mänskliga preferenser. I takt med att modellerna blivit mer kapabla har utvärderingen förskjutits från statiska benchmarktester mot mer dynamiska metoder som parvisa jämförelser och modellbaserad bedömning.
Centrala aktörer och bidrag
- OpenAI (t.ex. GPT-4-rapporten): introducerade storskalig användning av mänskliga preferenser och parvis utvärdering
- Anthropic: betonade strukturerad utvärdering, anpassning och konsekvens
- LMSYS (Zheng et al.): visade på LLM-as-a-judge och jämförande utvärderingsmetoder
- Stanford HELM-projektet: holistisk utvärdering över flera dimensioner och scenarier
Informationsåtervinning
Vad fältet handlar om
Informationsåtervinning studerar hur relevant information kan hittas och rangordnas i stora, brusiga datamängder. Utvärderingen fokuserar inte på absolut korrekthet, utan på relevans — om den återfunna informationen är användbar för en viss uppgift.
Centrala aktörer och bidrag
- TREC (Text REtrieval Conference): etablerade standarder för relevansbaserad utvärdering
- Gerard Salton: grundläggande arbete om vektorrumsmodeller och rangordning
- Stephen Robertson: probabilistiska modeller för informationssökning (t.ex. BM25)
Beslutsvetenskap
Vad fältet handlar om
Beslutsvetenskap undersöker hur individer och organisationer fattar beslut under begränsningar som brist på information, tidspress och kognitiva begränsningar. Fältet utmanar antagandet om fullt rationellt beslutsfattande.
Centrala aktörer och bidrag
- Herbert Simon: begränsad rationalitet och satisfiering
- Daniel Kahneman & Amos Tversky: tumregler, bias och beslutsfattande under osäkerhet
- Gerd Gigerenzer: ekologisk rationalitet och adaptiva tumregler
Risk och styrning
Vad fältet handlar om
Ramverk för risk och styrning beskriver hur organisationer strukturerar beslutanderätt, ansvar, kontrollmekanismer och riskhantering i komplexa miljöer. I det här sammanhanget handlar styrning inte bara om efterlevnad, utan om att säkerställa att beslut fattas på rätt nivå, med rätt information och med tydligt ägarskap.
Centrala aktörer och bidrag
- COBIT (ISACA): erbjuder ett heltäckande ramverk för styrning och ledning av verksamhetens IT, med fokus på samordning mellan verksamhetsmål, kontrollmål och beslutanderätt
- CGEIT body of knowledge: fokuserar på styrning av verksamhetens IT, inklusive värdeleverans, riskoptimering och resurshantering
- ISO 31000: principer och riktlinjer för riskhantering under osäkerhet
- EU:s AI Act: framväxande europeiskt regelverk för AI-system med hög risk, med betoning på spårbarhet, ansvar och styrning
Tillsammans stödjer de här fälten en förskjutning från att utvärdera textresultat till att utvärdera beslutsstödsystem som verkar under osäkerhet.
Begränsningar och fortsatt arbete
Det här ramverket är ett första försök att formalisera utvärdering av beslutsstödsystem under osäkerhet. Därför finns också flera begränsningar.
För det första bygger ramverket på strukturerad subjektiv bedömning snarare än objektivt facit. Mekanismer som parvisa jämförelser, mätning av samstämmighet och referensfall minskar godtycklighet, men eliminerar den inte. Utfallet i utvärderingen är fortfarande känsligt för hur bedömningsramar utformas och vilka antaganden utvärderare gör.
För det andra är de nuvarande kriterierna heuristiska och induktiva. De är härledda från teori — beslutsvetenskap, informationsåtervinning och styrning — samt tidiga empiriska observationer, men har ännu inte validerats genom storskaliga eller longitudinella studier.
För det tredje utgår ramverket från en relativt sammanhållen beslutskontext (CIO / styrning på ledningsnivå). Om det ska användas i andra domäner eller beslutsmiljöer kan det behöva anpassas.
För det fjärde är balansen mellan kalibrering av osäkerhet och handlingsbarhet fortfarande svår att mäta exakt. Med tiden kan mer formella proxyvariabler och mått behövas för att bedöma den avvägningen mer tillförlitligt.
Fortsatt arbete
Den fortsatta utvecklingen kommer att fokusera på att göra det här konceptuella ramverket till ett utvärderingssystem som förbättras över tid.
Viktiga riktningar är:
-
Kalibrering och jämförelse av utvärderare
Systematisk mätning av överensstämmelse mellan mänskliga utvärderare och LLM-baserade bedömare, inklusive stabilitet över upprepade körningar. -
Utveckling av LLM-as-a-judge
Förfining av utvärderingsprompter och scheman för att förbättra konsekvens, minska bias och möjliggöra jämförande utvärdering i större skala. -
Utökning av dataset ("golden set")
Uppbyggnad av en större och mer varierad referensmängd för att förankra utvärderingen och stödja statistisk analys. -
Formalisering av mått
Utveckling av tydligare och mer testbara proxyer för dimensioner som användbarhet för beslut, disciplin i osäkerhet och graden av överdrivna påståenden. -
Modelloptimering
Användning av utvärderingssignaler för att stödja finjustering eller destillering av mindre och mer effektiva modeller optimerade för uppgifter inom styrningstriage. -
Iteration av prompt- och systemdesign
Löpande förbättring av prompter, pipelines och strategier för informationshämtning utifrån observerade utvärderingsresultat.
Det långsiktiga målet är att utveckla detta till ett slutet system för utvärdering och förbättring, där resultat kontinuerligt bedöms, jämförs och används för att förbättra både modeller och utvärderingsmetoder.
Slutsats
Det här perspektivet flyttar AI-utvärdering från en fråga om textkvalitet till en fråga om beslutsstöd under osäkerhet.
Genom hela texten framträder en tydlig position:
- Verklig styrning sker med ofullständiga data, tidspress och konkurrerande tolkningar.
- Under dessa förhållanden är korrekthet och fullständighet otillräckliga mål för utvärdering.
- Det avgörande är om resultaten ger rätt kalibrerade och handlingsbara beslutssignaler.
Det föreslagna angreppssättet kombinerar därför:
- Jämförande utvärdering (vilken rapport är mest användbar för beslutsfattande)
- Strukturerade dimensioner förankrade i beslutsvetenskap, informationsåtervinning och styrningsprinciper i linje med COBIT
- Tydlig hantering av subjektivitet, där man erkänner glappet mellan analytisk kvalitet, organisatoriskt genomslag och beslutspåverkan
I praktiken implementeras detta som en första metodversion: flera modeller, till exempel Gemini och Mistral, genererar rapporter på samma data; resultaten utvärderas i LangSmith; och utfallet används för att styra modellval, promptdesign och vidare systemutveckling. Metoden är medvetet iterativ och utformad för att utvecklas till ett slutet utvärderingssystem.
Begreppsligt placerar ramverket Kanita som ett lager som verkar uppströms den formella styrningen — där svaga signaler struktureras till triageringsbeslut som ligger i linje med COBIT-principer (EDM/APO/BAI) samtidigt som de förblir kalibrerade mot osäkerhet.
Den viktigaste implikationen är inte att osäkerhet kan tas bort, utan att den kan göras handlingsbar.
Målet är inte perfekt analys.
Det är rätt beslutssignal, på rätt nivå, med kalibrerad säkerhet, från ofullkomliga data.